
Can ChatGPT interpret topic models?


Large language models like ChatGPT give the impression of comprehension, offering (well, a lot of the time) fluent responses to even the most abstract prompts. But what happens when we ask ChatGPT to interpret data-driven models of language—can it, for example, make ‘sense’ of topic models?
To test that proposition, I presented ChatGPT with an existing set of topic models, previously published in Digital Scholarship in the Humanities. The models, taken from the journal article ‘Topic modelling literary interviews from The Paris Review’, analyse over 70 years’ worth of literary interviews from the Review’s famed ‘Writers at Work’ series. This collaboration between Derek Greene, Daragh O'Reilly and myself was responding to a simple question: what do writers speak about when asked to speak about writing?
Topic modelling is a method used in natural language processing to uncover latent thematic structures in large collections of texts. Topic modelling is a form of unsupervised machine learning, which means the algorithm discovers patterns without being given explicit categories or labels in advance. Ted Underwood’s explanation of how it works remains the most intuitive around.
Among the most widely used topic modelling techniques is Latent Dirichlet Allocation (LDA), developed by David Blei and colleagues in the early 2000s. The principle behind LDA is deceptively simple. Imagine that each document in a corpus is made up of multiple topics, and each topic is made up of a distribution of words. The model works backwards from the actual words in the documents to infer these hidden—or ‘latent’—topics. It does this probabilistically: it assumes that each word in a document was generated by some mixture of topics, and iteratively adjusts its parameters until the most likely configuration of topic-word and document-topic distributions is found.
In The Paris Review study, we favoured Non-negative Matrix Factorisation (NMF) over LDA. NMF is a dimensionality reduction technique often used in topic modelling as an alternative to LDA. Like LDA, NMF attempts to uncover latent structures—again, what we call topics—in large textual corpora, but it does so through linear algebra rather than probabilistic modelling. It is valued for its interpretability and its tendency to yield more distinct and less overlapping topics than LDA.
Whichever approach one uses, the result is a set of topics, each represented by a list of words that are statistically associated with one another across the corpus. Crucially, these are not semantically defined categories; they are artefacts of co-occurrence and frequency. It is up to the human interpreter to look at the top words in each topic and assign meaning (this is the key point, because this is the task I’ve set ChatGPT). This act of interpretation, often glossed over in methodological write-ups, is as much a hermeneutic exercise as it is a technical one.
It might be useful for readers unfamiliar with topic models to think of them as thematic analyses, wherein documents are represented as word groupings which can indicate ideas (i.e., ‘topics’) central to the corpus. For example, if one topic models The New York Times, they will see a topic made up of words relating to finance (stock, market, percent, fund, investors, funds, companies, stocks, investment, and trading) as well as one on sports (game, knicks, nets, points, team, season, play, games, night, and coach), which includes the name of New York teams like the Knicks and Nets (Blei 2013). These are useful as illustrative topics because they make sense; one would expect ‘finance’ and ‘sports’ to emerge as topics in an analysis of most newspapers. Of course, the fact that these topics have been identified as ‘finance’ and ‘sports’ is purely interpretive: topic models produce sets of words (in this case, ten words per topic), and it is through a critical intervention that sense is made of these groupings.
In practice, the quality and coherence of a topic depend on many factors: the size of the corpus, the number of topics specified by the modeller, and the pre-processing of the text (such as stopword removal and stemming). There is always a degree of fuzziness. Some topics are crisp and easily nameable, while others are ambiguous or overlapping. And yet, it is precisely this ambiguity that makes topic modelling so useful for scholars in the humanities: it reveals patterns that are suggestive rather than prescriptive, opening up space for new interpretations.
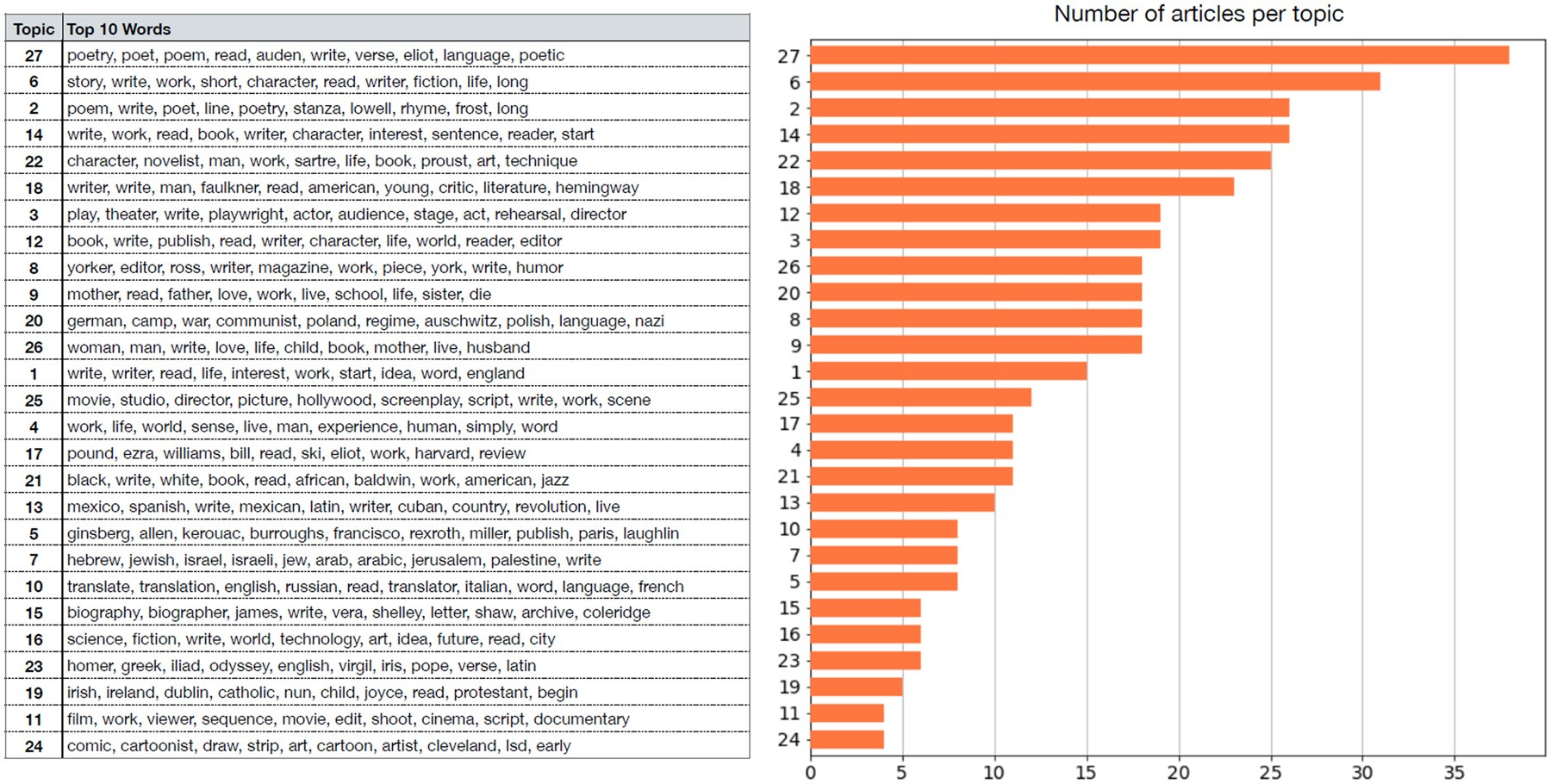
Any good topic model should give you a lot of what a critic might consider ‘obvious’ (if it’s all fuzziness, you’ve probably done something wrong). In the original paper, we picked out a number of topics that we interpreted as ‘noteworthy’.
Our model identified—or, more accurately, we interpreted—two distinct topics around film: Topic 11 represents film as artistic practice, with interviews featuring directors such as Michael Haneke, Woody Allen, and Frederick Wiseman. Topic 25 captures film as industry and commerce, represented by interviews with screenwriters like Richard Price, Thomas McGuane, and John Dunne. This division highlights a clear semantic separation between the art of film-making and the commercial realities surrounding it.
Topic 16 relates to science fiction, with Ursula K. Le Guin and Doris Lessing among the most representative interviewees,1 challenging masculinist assumptions about the genre.
Topic 24 surprisingly captures a theme around comics and cartoons—an unexpected emergence given the canonical status of The Paris Review interview series.
While an explicit gender-focused topic was largely absent, Topic 26 (woman, man, write, love, life, child, book, mother, live, husband) might be interpreted as a partial reflection on gender roles and personal life.
Matters of techne, that is, the craft and technical aspects of writing, were notably underrepresented—as one of our reviewers remarked, ‘where are the pencils?’
Several topics are strongly oriented around national and political histories: Topic 20 addresses Germany, Poland, and the Holocaust, with references to Nazi and communist regimes; Topic 7 concerns the Israeli–Palestinian conflict; Topic 13 relates to Latin American literature, often framed through revolutionary discourse; and Topic 19 captures Irish literature, with particular emphasis on religion and the influence of James Joyce.
Topic 27 is the most dominant, organised around poetry and literary influence, heavily featuring Auden and Eliot (both George and T.S.). Topic 17 focuses on Modernism, particularly the role of Harvard University and its publication The Harvard Advocate. Topic 5 concerns the Beat Generation, with central figures such as Allen Ginsberg and Jack Kerouac.
Finally, Topic 18 reflects canonical American male writers like Faulkner and Hemingway, whereas Topic 21 focuses on African-American literature and race, with James Baldwin as a key figure and Toni Morrison emerging as a representative voice. This separation underscores racial divisions that are detectable at the macro level of the corpus.
So the question is, when fed the same topic models, what does ChatGPT come up with?
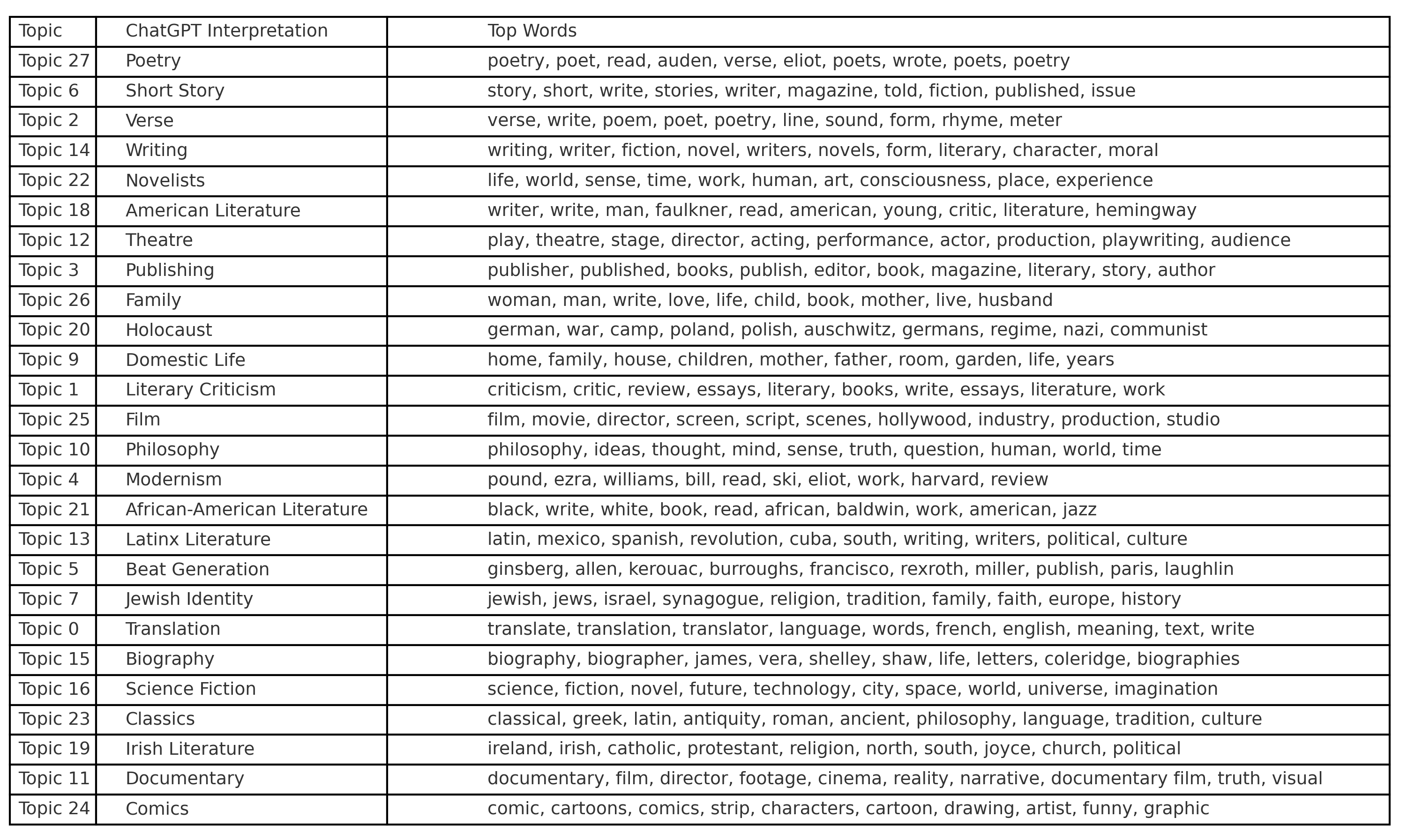
When fed the results of a topic model, ChatGPT does an extremely good job making sense of the associations between words, providing plausible and recognisable labels for the topics: ‘Poetry’, ‘Short Story’, ‘Beat Generation’, ‘Science Fiction’ etc. It can efficiently—and I would argue, quite accurately—label topics based on the co-occurrence of terms, mapping surface-level semantic structures with considerable fluency. That ChatGPT performs so well at this task is hardly surprising. Large language models are, after all, statistical machines trained precisely to predict and reproduce patterns of language based on massive corpora of text. They are, in a sense, built to recognise and extrapolate from the kinds of lexical associations that topic models surface. When confronted with a cluster of related terms, ChatGPT is simply doing what it has been optimised to do: drawing on its training to supply a coherent label that fits the statistical context. In this sense, topic modelling and large language models share a conceptual kinship: both operate on the detection of distributional regularities across large bodies of text, albeit with different goals and at different scales.
Again expected, when placed alongside our critical reading of the model's output, there are differences. ChatGPT identified ‘Film’ as a topic but did not discern the crucial division between film as artistic practice (Topic 11) and film as industry and commerce (Topic 25)—a division that, when interpreted contextually, reveals how The Paris Review interviews position creative labour in relation to the broader structures of cultural production. Of course, maybe it is our interpretation that is wrong, and as can be possible with distant reading (and maybe literary criticism more broadly), we over-interpreted the significance of our models. Maybe ChatGPT’s interpretation of the two film topics—that one is about ‘film’ and the other ‘documentaries’—is the more appropriate ‘reading’.
Where ChatGPT saw ‘American Literature’ as a singular domain (Topic 18), we argued for a significant bifurcation between canonical American male authors like Faulkner and Hemingway, and African-American literary traditions centred around figures like Baldwin and Morrison (Topic 21).
When asked to analyse the topics for their literary and cultural significance, ChatGPT was less impressive, but still, not unimpressive. It did attempt to make that argument that the number of historical or geographically-situated topics reflects a ‘broadly inclusive approach to cultural representation’, something with which critics might disagree: participants in interviews with The Paris Review are overwhelmingly male. But Rebecca Roach argues the opposite: ‘To a real extent, The Paris Review took modernism back from the critics and universities, rendering it to the writers, giving them a central role in shaping the reception of their work.’
ChatGPT argued that the models suggest the corpus is particularly concerned with identity, memory, and trauma, a finding we did not expand upon.
It also spotted a notable cluster encompassing domains that are arguably para-literary or extra-literary: ‘Publishing’ (Topic 3), ‘Film’ (Topic 25), ‘Theatre’ (Topic 12), and ‘Documentary’ (Topic 11) indicate an expanded field of cultural production that goes beyond traditional literary forms. Like us, it remarked on the inclusion of ‘Comics’ (Topic 24), suggesting an openness to popular culture and the visual text. These clusters reflect a disciplinary trend towards multimodal analysis and the study of media ecologies, a broader trend we failed to fully appreciate.
There are subtle differences: where ChatGPT saw ‘poetry’, we read ‘influence’. Where it saw ‘Irish literature’, we saw ‘Irish literature and religion’. It did not register the racial divisions underpinning American literature in the twentieth century. It did not remark upon the absence of gendered discourse in a corpus dominated by male voices. It did not, as already noted, detect the tension between creative labour and commercial production that we found latent in the way The Paris Review framed discussions of film.
But again, our interpretations are not necessarily better, but they are different.
While philosophically, we all know that the machine describes and the human interprets (yawn!, I know), the functional reality is that ChatGPT offered plausible thematic groupings based on lexical proximity, and it did, though to a lesser extent than we human readers, situate these patterns within wider cultural, historical, or political frameworks.
Large language models are extraordinarily powerful tools for identifying surface patterns, but they are not as robust when it comes to hermeneutic engagement, for recognising that what is present in a corpus is often as meaningful as what has been effaced or marginalised.
Like most forms of distant reading, topic models are provocations, starting points for interpretation, not replacements for it. ChatGPT can aid that process by offering rapid, often useful labels; but it cannot—and should not—replace the human work of asking deeper questions about meaning, structure, and absence. If anything, this exercise reminds us that even as we embrace computational tools, the fundamental tasks of criticism—reading closely, thinking historically, interpreting responsibly—remain as vital as ever.
But anyone who thinks ChatGPT cannot critique in its own right is sorely mistaken, or is too hung up on the old ‘I think, therefore I am’ view of intelligence.
If anything, this little experiment demonstrates that ChatGPT is not unthinking. Its readings may be shallower (and maybe they’re not), but they are nonetheless readings: structured, inferential, and (occasionally) provocative. What the outputs of models like ChatGPT lack is not intelligence per se, but intentionality. They do not argue with purpose; they do not stake claims in contested critical debates. Their ‘critiques’ are collages of prior language, not interventions made by a self-aware agent engaged in the messy project of meaning-making. In this sense, ChatGPT's interpretations of our topic models are valuable—not because they offer the last word, but because they offer another beginning. They provide an opportunity to think about what we prioritise in reading, what we count as interpretation, and how we might responsibly integrate computational assistance into the practice of scholarship without surrendering the critical imagination that gives such work its purpose.
Ultimately, then, this exercise reaffirms what literary scholars and critics have long known but perhaps needed to be reminded of: that interpretation is not just an act of recognition, but of judgement. It is an ethical engagement with language, history, and culture. ChatGPT cannot replicate that process, but it can, whether or not we want to admit it, assist in that process, even improve it. It’s a grim conclusion, but readers of the human sort aren’t always as special as we like to think. Maybe (and yes, I’m over-indulging a little here), intentionally does not matter as much as we pretend.
To determine the most 'representative' interviewees for this topic, we examined the interviews that exhibited the highest proportional allocation of Topic 16 according to the topic modelling output. In this context, interviews with Ursula K. Le Guin and Doris Lessing emerged as those in which Topic 16 had the greatest presence, suggesting that their discussions most closely aligned with the thematic cluster captured by this topic.